audio-driven spokesperson
photorealistic audio-driven hand gesture generation solution with personalized registration
October 2022
The project was done at Prof. Yebin Liu's lab.
showcases
my personalized registration, audio from internet
(note: no driven facial expression here. the demostration here did not consider semantic gesture (e.g., number pose, victory pose, ...) )
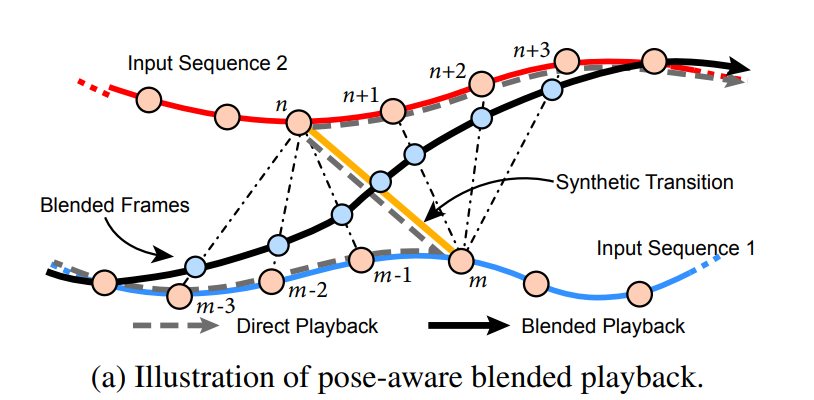
pipeline
The code implementation followed the innovative generation pipeline in [1]. When searching for pose sequence aligning with the audio input and interpolating new poses, we merged robust pose estimation frameworks [2] [3] into the pipeline, thus allowing the network to generate photorealistic human figure with accurate and stable 3D representation of body skeleton and hand joints as well as the surface geometry condition as key inputs for light flow estimation.

references
- Yang Zhou, Jimei Yang, Dingzeyu Li, Jun Saito, Deepali Aneja, and Evangelos Kalogerakis. 2022. Audio-driven Neural Gesture Reenactment with Video Motion Graphs. In IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, Louisiana.
- Hongwen Zhang*, Yating Tian*, Xinchi Zhou, Wanli Ouyang, Yebin Liu, Limin Wang, and Zhenan Sun. 2021. PyMAF: 3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop. Oral Presentation in International Conference on Computer Vision (ICCV).
- Hongwen Zhang, Yating Tian, Yuxiang Zhang, Mengcheng Li, Liang An, Zhenan Sun, and Yebin Liu. 2023. PyMAF-X: Towards Well-aligned Full-body Model Regression from Monocular Images. In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).